9450 SW Gemini Drive #32865
Beaverton, Oregon, 97008-7105
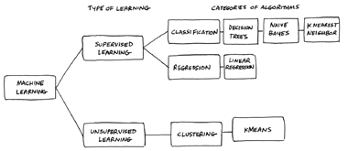
In my previous article, Machine Learning Algorithms, I explain what machine-learning algorithms are and describe the following commonly used algorithms:
Based on the descriptions of the machine learning algorithms I presented in that post, you could already start to figure out which algorithm would be best for answering a certain type of question or solving a certain type of problem. In this article, I provide some additional guidance.
Your choice of algorithm generally depends on what you want the algorithm to do:
When choosing an algorithm, consider a more empirical (experimental) approach. After narrowing your choice to two or more algorithms, you can train and test the machine using each algorithm with the data you have and see which one delivers the most accurate results. For example, if you're looking at a classification problem, you can run your training data on K-nearest neighbor and Naïve Bayes and then run your test data through each of them to see which one is best able to accurately predict which class a particular unclassified entity belongs to.
There is a more formal method for choosing a machine-learning algorithm, as presented in the following sections.
The first step is to figure out the nature of the problem you are trying to solve via machine learning. Categorize the problem by both input and output:
1. Categorize the problem by input:
2. Categorize the problem by output:
The data you have also informs your choice of machine-learning algorithm:
Conditions beyond your control may influence your choice of machine-learning algorithm. For example:
Also, ask the following questions:
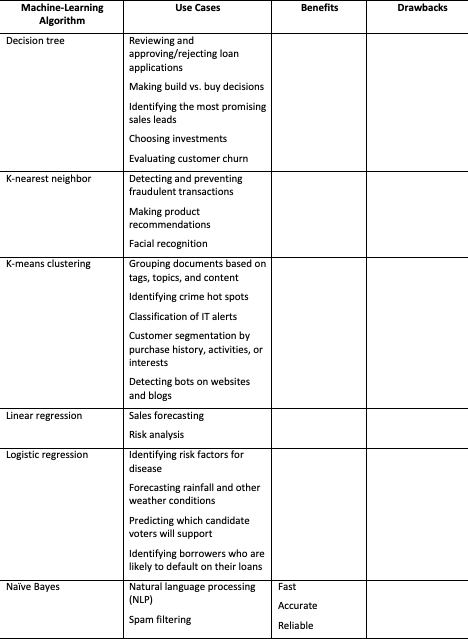
The final step involves making your choice. The following table provides a list of algorithms along with specific use cases in which each application may be most suitable, as well as the pros and cons of each algorithm.
Remember, prior to building a machine learning model, it is always wise to consult others on your data science team, particularly your resident data scientist, if you are fortunate enough to have one. Choosing a machine learning algorithm is a combination of art and science, so you’re likely to benefit by having someone look at the problem from another perspective.
In one of my previous articles What Is Machine Learning? I explain the basics of machine learning (ML) and point out the fact that big data plays a key role in ML. However, I stopped short of explaining the connection between ML and big data in detail. In this article, I take a deeper dive into the important role that big data plays in machine learning.
Machine learning requires the following four key components:
Machines learn in the following three ways:
As you can see, data is important for machine learning, but that is no surprise; data also drives human learning and understanding. Imagine trying to learn anything while floating in a deprivation tank; without sensory, intellectual, or emotional stimulation, learning would cease. Likewise, machines require input to develop their ability to identify patterns in data.
The availability of big data (massive and growing volumes of diverse data) has driven the development of machine learning by providing computers with the volume and types of data they need to learn and perform specific tasks. Just think of all the data that is now collected and stored — from credit and debit card transactions, user behaviors on websites, online gaming, published medical studies, satellite images, online maps, census reports, voter records, financial reports, and electronic devices (machines equipped with sensors that report the status of their operation).
This treasure trove of data has given neural networks a huge advantage over the physical-symbol-systems approach to machine learning. Having a neural network chew on gigabytes of data and report on it is much easier and quicker than having an expert identify and input patterns and reasoning schemas to enable the computer to deliver accurate responses (as is done with the physical symbol systems approach to machine learning).
In some ways, the evolution of machine learning is similar to how online search engines developed over time. Early on, users would consult website directories such as Yahoo! to find what they were looking for — directories that were created and maintained by humans. Website owners would submit their sites to Yahoo! and suggest the categories in which to place them. Yahoo! personnel would then review the user recommendations and add them to the directory or deny the request. The process was time-consuming and labor-intensive, but it worked well when the web had relatively few websites. When the thousands of websites proliferated into millions and then crossed the one billion threshold, the system broke down fairly quickly. Human beings couldn’t work quickly enough to keep the Yahoo! directories current.
In the mid-1990s Yahoo! partnered with a smaller company called Google that had developed a search engine to locate and categorize web pages. Google’s first search engine examined backlinks (pages that linked to a given page) to determine each page's relevance and relative importance. Since then, Google has developed additional algorithms to determine a page’s rank; for example, the more users who enter the same search phrase and click the same link, the higher the ranking that page receives. With the addition of machine learning algorithms, the accuracy of such systems increases proportionate to the volume of data they have to draw on.
So, what can we expect for the future of machine learning? The growth of big data isn't expected to slow down any time soon. In fact, it is expected to accelerate. As the volume and diversity of data expand, you can expect to see the applications for machine learning grow substantially, as well.
Machine learning plays a key role in artificial intelligence. Machines can be fed large volumes of data and, through supervised and unsupervised learning, analyze that data in various ways to predict outcomes and reveal deeper insights into the data. Four types of machine learning algorithms are commonly used to perform these different types of analysis:
The ability of machines to learn by engaging in different types of analysis is impressive, but machine learning becomes truly amazing when these abilities are applied to real-world tasks. In this post, I describe three examples of the use of artificial intelligence in business.
When most people hear the term "artificial intelligence," they think of robots — C-3PO and R2D2 in Star Wars; Commander Data in Star Trek 🖖; the T-800 played by Arnold Schwarzenegger in The Terminator; Robot in Lost in Space; and Hal, the Heuristically programmed Algorithmic computer that runs the spaceship Discovery in 2001: A Space Odyssey.
The robots of today are not quite as impressive, but they are certainly moving in that direction. Today's robots are designed primarily to perform physical labor — assembling products, painting vehicles, delivering packages, and vacuuming floors.
Although robots are still highly specialized, they were even more so in the past. Older robots needed highly specific programming to tell them exactly what to do. These older robots are still in use today; for example, in computer-aided manufacturing (CAM), a program may instruct a drill press to drill holes in specific locations to specific depths on a part.
Today's robots are more sophisticated. With the development of physical symbol systems and machine learning, robots can now adapt to changing environments. For example, many robotic vacuum cleaners use a form of symbolic AI to map different rooms and determine the most effective paths to take to vacuum the entire floor. When they’re losing their charge, they can return to home base and dock with the charging station. To prevent accidents, they know to avoid stairs and other obstacles.
A more complex example is the self-driving car. The newest vehicles employ an artificial neural network and are outfitted with a host of complex sensors that feed data into the network. These driverless cars can figure out how to navigate from point A to point B as many people already do — by following directions from a program like Google Maps. However, they must also be able to read and interpret street signs, avoid running over pedestrians, adjust to driving conditions, and much more.
Nobody can program into a self-driving car all of the possible variables the car may encounter, so it must be able to learn. Early versions of self-driving cars have steering wheels, an accelerator, and a brake pedal and require a human in the driver’s seat who can override the automated system when necessary. This approach provides a form of supervised learning in which the driver corrects the neural network when it makes a mistake.
If you set out to make a sophisticated robot like those you see in the movies and on TV, one of the first things you need to do is enable the robot to understand and communicate in spoken language. This has always been a challenge for AI developers, and they are meeting this challenge through the technology of natural language processing (NLP). If you’ve met Siri, Alexa, or Cortana or used talk-to-text on your smartphone, you’ve already experienced NLP. As you speak, the computer identifies the words and phrases and appears to understand what you said.
NLP makes computer-human interactions more human. For example, if you have an Amazon Fire TV Stick for streaming movies and TV shows, you can hold down the speaker button and say "Find movies directed by Stanley Kubrick," and the Fire Stick will list that director's movies — at least the movies available for viewing. Using traditional programming, you would never be able to develop software that could anticipate this question, figure out what you wanted, and deliver a complete list of movies. Just getting the computer to recognize different voices asking the same question would be a monumental task.
However, big data combined with machine learning is up to the task. Big data feeds the machine everything it needs to identify words and phrases, along with an enormous database of movie and TV show titles, actors, directors, plot descriptions, and more. Machine learning provides the means for understanding words and phrases spoken in different ways and evolving when corrected for making mistakes. You may notice that the longer you use a natural language processing system or device, the better it gets at understanding what you say.
The Internet of Things (IoT) refers to the large and growing collection of everyday objects that connect to the Internet and to one another. These devices include smart thermostats that learn your daily habits and adjust automatically to keep you comfortable, smart watches that can track your daily activity and let you know when you’re meeting your fitness goals, and smart refrigerators that can tell you when your milk is past its expiration date.
And because smart devices are connected to the Internet, you can control them remotely. For example, you can put a casserole in the oven before you leave home in the morning and then turn on the oven from your smartphone 15 minutes before leaving work, so that the casserole is done by the time you get home.

Certain devices can even communicate with one other. For example, your alarm clock can tell the coffee machine when to start brewing. Your smart watch can tell your smart locks to unlock the doors when you approach your home or turn on music when you enter your living room.
It is hard to imagine AI expanding because it is already being applied so broadly in businesses, homes, government, and more. Instead of looking to the future and seeing more AI, I look to the future and see better AI — better robots, much better natural language processing, and fewer glitches in IoT devices. Perhaps, someday far into the future, we will begin to see robots that can do more than just follow us around with our luggage and deliver groceries.
Like people, machines can learn through supervised and unsupervised machine learning, but human learning differs from machine learning. With humans, supervised learning consists of formal education. An instructor presents the material, students study it and are tested on it, and areas of weakness are addressed, hopefully to the point at which students achieve mastery in that given subject area. Unsupervised learning is experiential, often referred to as "common sense." You venture out in the world and engage in daily activities, learning on your own and from making mistakes.
Machine learning differs in that it involves only a couple forms of learning, and those are determined by what you want the machine to do:
With supervised learning, a human trainer labels items in a small data set often referred to as the training data set. The machine has an advantage of knowing how the human trainer has classified the data. For example, suppose you want to train a machine to be able to distinguish between spam email messages and not-spam email messages. You feed several examples of spam messages into the machine and tell the machine, "These are spam." Then, you feed several examples of not-spam messages into the machine and tell it, "These are not spam."
The machine identifies patterns in both message groups — certain patterns that are characteristic of spam and other patterns characteristic of not-spam. Now, when you feed a message into the machine that is not labeled spam or not-spam, the machine should be able to tell whether the message is or is not spam.
Unfortunately, machines make mistakes. A certain message may not have a clear pattern that characterizes it as either spam or not-spam, so it may send some messages that are not spam to the Spam folder and allow some spam messages to reach your Inbox. Your machine clearly needs more training.
Additional training occurs when you mark a message in the Spam folder as "not spam," or when you move a spam message from your inbox to the spam folder. This provides the machine with valuable feedback that enables it to fine-tune its neural network, increasing its accuracy.
Supervised learning tends to be more useful than unsupervised learning in the following applications:
Classification and regression are both considered to be predictive because they can be used to forecast the probability that a given input will result in a given output. For example, if you use a regression algorithm to identify a relationship between family income and high school graduation rates, you can use that relationship to predict a student's likelihood of graduating by looking at the student's family income.
With supervised learning, you feed the machine a data set and instruct it to group like items without providing it with labeled groups; the machine must determine the groups based on similarities and differences among the items in the data set.
For example, you might feed 1000 medical images into a machine and have it group the images based on patterns it detects in those images. The machine creates 10 groups and assigns images to each group. A doctor can then examine the different groups in an attempt to figure out why the machine grouped the images as it did. The benefit here is that the machine may identify patterns that doctors never thought to look for — patterns that may provide insights into diagnosis and treatment options.
Unsupervised learning tends to be more useful than supervised learning in the following applications:
Clustering and association are considered to be descriptive, as opposed to predictive, because they identify patterns that reveal insights into the data.
When starting your own artificial intelligence project, carefully consider the available data and what you want to do with that data. If you already have well defined categories that you want the machine to use to classify input, you probably want to stick with supervised learning. If you’re unsure how to group and categorize the data or you want to look at the data in a new way, unsupervised learning is probably the better approach because it enables the computer to identify similarities and differences you may have never considered otherwise.
Early attempts at artificial intelligence (AI) produced computers that were proficient at solving specific types of problems, along with expert systems that can perform tasks that normally require human intelligence. These tasks might include finding the fastest route from point A to point B for example, or translating text from one language to another.
These AI applications were generally built on the foundation of physical symbol systems. A physical symbol system is any device that stores a set of patterns (symbols) and uses a number of processes to create, modify, copy, combine, and delete symbols. Think of symbols as the mental images that form in your brain as you observe and experience the world.
AI applications rely primarily on pattern-matching to do their jobs. For example, a translation program stores words, phrases, and grammar rules for two or more languages. When a user requests a translation, say from English to Spanish, the application looks up the English words or phrases that the user supplied, finds the Spanish equivalents, and then attempts to stitch together the Spanish words and phrases, following the grammar rules programmed into the system.
The limitation with such a system is that it is fixed — it cannot learn or adapt on its own. In the context of a translation program, the system may not choose the most accurate word based on the intended meaning in the context of a sentence, and it will continue to make the same mistake in future translations unless the programmer steps in and makes an adjustment.
This limitation becomes more of an issue in situations in which the environment changes rapidly; for example, when anti-malware software must adapt quickly to identify, block, and eliminate evolving threats. Such threats evolve too quickly for anti-malware developers to update their databases. They need a way for the software to automatically identify new potential threats and adjust accordingly. In other words, the anti-malware must learn.
To overcome the limitations of early AI, researchers started to wonder whether computers could be programmed to learn new patterns. Their curiosity led to the birth of machine learning — the science of getting computers to perform tasks they weren't specifically programmed to do. So what is machine learning?
Machine learning got its start very shortly after the first AI conference in 1956. In 1959, AI researcher Arthur Samuel created a program that could play checkers. This program was different. It was designed to play against itself to improve its performance. It learned new strategies from each game it played and after a short period of time began to consistently beat its own programmer.
A key advantage of machine learning is that it doesn't require an expert to create symbolic patterns and list out all the possible responses to a question or statement. On its own, the machine creates and maintains the list, identifying patterns and adding them to its database.
One interesting application of machine learning is in the area of fraud detection and prevention. Your credit card company, for example, monitors your charges—where you use your card, what you buy, the average amount you charge to the card, and so on. If the system detects anything that breaks the pattern of your typical card use, it triggers a fraud alert and may even automatically place your account on hold.
Machine learning has become one of the fastest growing areas in AI at least partially because the cost of data storage and processing has dropped dramatically. With virtually unlimited storage and compute available via the cloud, companies can now create and store extremely large data sets that can be analyzed by clusters of high-speed processors to identify patterns, trends and associations.
Machine learning enables companies to extract valuable information and insight from their data — information and insight that they may never have imagined was there.
Developers use various machine-learning algorithms to enable machine learning. (An algorithm is a process or set of rules to be followed in calculations or other problem-solving operations.) Machine learning algorithms enable AI applications to identify statistical patterns in data sets. Depending on the algorithms used, machines can learn in one of the following three ways:
Just as learning is key to human intelligence, machine learning is a key element of artificial intelligence. Without learning, a machine only has the potential to perform the tasks it was programmed to do. With machine learning, machines can take the next step — increasing their knowledge, sharpening their skills, and developing new skills beyond what they were programmed to have.
In my previous article, Neural Network Hidden Layers, I presented a simple example of how multi-layer artificial neural networks learn. At a more basic level is the perceptron — a single-layer neural network. The perceptron history is worth looking at because it sheds light on how individual neurons within a neural network function. If you know how a perceptron functions, you know how an artificial neuron functions.
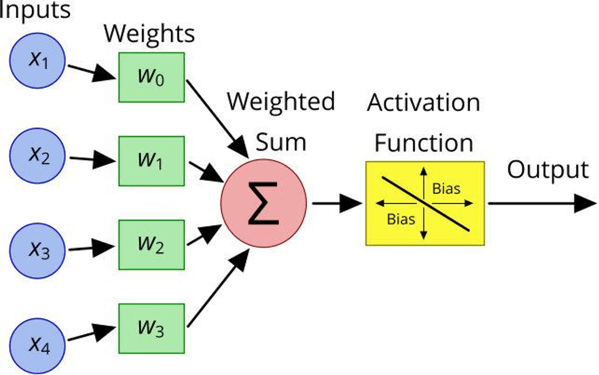
A perceptron consists of five components:
Basically, here's how a perceptron works:
Weights and bias are primarily responsible for enabling machine learning in a neural network. The neural network can adjust the weights of the various inputs and the bias to improve the accuracy of its binary classification system.
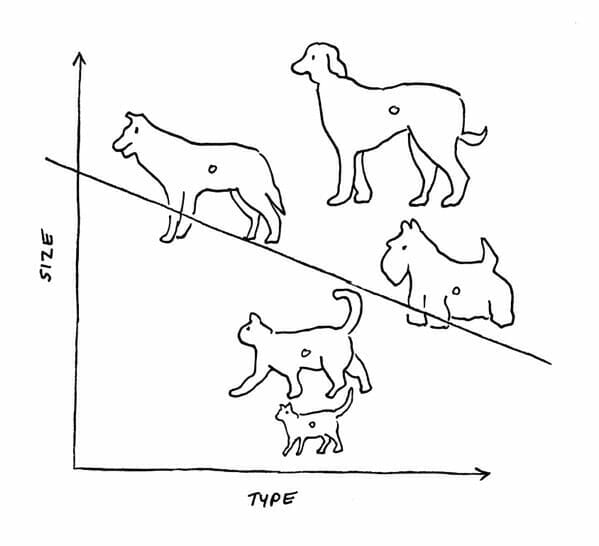
For example, the figure below illustrates how the output function of a perceptron might draw a line to distinguish between pictures of cats and dogs. If one or more dog pictures ended up on the line or slightly below the line, bias could be used to adjust the position of the line so it more precisely separated the two groups.
Frank Rosenblatt invented the perceptron in 1958 while working as a professor at Cornell University. He then used it to build a machine, called the Mark 1 Perceptron, which was designed for image recognition. The machine had an array of photocells connected randomly to neurons. Potentiometers were used to determine weights, and electric motors were used to update the weights during the learning phase.
Rosenblatt's goal was to train the machine to distinguish between two images. Unfortunately, it took thousands of tries, and even then the Mark I struggled to distinguish between distinctly different images.
While Rosenblatt was working on his Mark I Perceptron, MIT professor Marvin Minsky was pushing hard for a symbolic approach. Minsky and Rosenblatt debated passionately about which was the best approach to AI. The debates were almost like family arguments. They had attended the same high school and knew each other for decades.
In 1969 Minsky co-authored a book called Perceptrons: An Introduction to Computational Geometry with Seymour Papert. In it they argued decisively against the perceptron, showing that it would only ever be able to solve linearly separable functions and thus be able to distinguish between only two classes. Minsky and Papert also, mistakenly, claimed that the research being done on the perceptron was doomed to fail because of the perceptron's limitations.
Sadly, two years after the book was published, Rosenblatt died in a boating accident. Without Rosenblatt to defend perceptrons and with many experts in the field believing that research into the perceptron would be unproductive, funding for and interest in Rosenblatt's perceptron dried up for over a decade.
Not until the early 1980s did interest in the perceptron experience a resurgence, with the addition of a hidden layer in neural networks that enables these multi-layer neural networks to solve more complex problems.
Like people, machines can learn through supervised vs unsupervised learning. With supervised learning, a human labels the data. So the machine has an advantage of knowing the human definition of the data. The human trainer gives the machine a stack of cat pictures and tells the machine, “These are cats.” With unsupervised learning, the machine figures out on its own how to cluster the data.
Consider the earlier example of the marching band neural network. Suppose you want the band to be able to classify whatever music it’s presented, and the band is unfamiliar with the different genres. If you give the band music by Merle Haggard, you want the band to identify it as country music. If you give the band a Led Zeppelin album, it should recognize it as rock.
To train the band using supervised learning, you give it a random subset of data called a training set. In this case, you provide two training sets — one with several country music songs and the other with several rock songs. You also label each training set with the category of songs — country and rock. You then provide the band with additional songs in each category and instruct it to classify each song. If the band makes a mistake, you correct it. Over time, the band (the machine) learns how to classify new songs accurately in these two categories.
But let's say that not all music can be so easily categorized. Some old rock music sounds an awful lot like folk music. Some folk music sounds a lot like the blues. In this case, you may want to try unsupervised learning. With unsupervised learning you give the band a large variety of songs — classical, folk, rock, jazz, rap, reggae, blues, heavy metal and so forth. Then you tell the band to categorize the music.
The band won't use terms like jazz, country, or classical. Instead it groups similar music together and applies its own labels, but the labels and groupings are likely to differ from the ones that you’re accustomed to. For example, the marching band may not distinguish between jazz and blues. It may also divide jazz music into two different categories, such as cool and classic.
Having your marching band create its own categories has advantages and disadvantages. The band may create categories that humans never imagined, and these categories may actually be much more accurate than existing categories. On the other hand, the marching band may create far too many categories or far too few for its system to be of use.
When starting your own AI project, think about how you'd like to categorize your data. If you already have well defined categories that you want the machine to use to classify input, you probably want to stick with supervised learning. If you’re unsure how to group and categorize the data or you want to look at the data in a new way, unsupervised learning is probably the better approach; it’s likely to enable the computer to identify similarities and differences you would probably overlook.
Prior to starting an AI project, the first choice you need to make is whether to use an expert system (a rules based system) or machine learning. Basically the choice comes down to the amount of data, the variation in that data and whether you have a clear set of steps for extracting a solution from that data. An expert system is best when you have a sequential problem and there are finite steps to find a solution. Machine learning is best when you want to move beyond memorizing sequential steps, and you need to analyze large volumes of data to make predictions or to identify patterns that you may not even know would provide insight — that is, when your problem contains a certain level of uncertainty.
Think about it in terms of an automated phone system.
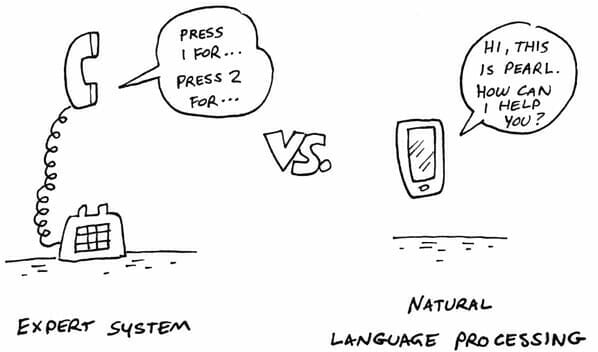
Older phone systems are sort of like expert systems; a message tells the caller to press 1 for sales, 2 for customer service, 3 for technical support and 4 to speak to an operator. The system then routes the call to the proper department based on the number that the caller presses.
Newer, more advanced phone systems use natural language processing. When someone calls in, the message tells the caller to say what they’re calling about. A caller may say something like, “I’m having a problem with my Android smart phone,” and the system routes the call to technical support. If, instead, the caller said something like, “I want to upgrade my smartphone,” the system routes the call to sales.
The challenge with natural language processing is that what callers say and how they say it is uncertain. An angry caller may say something like “That smart phone I bought from you guys three days ago is a piece of junk.” You can see that this is a more complex problem. The automated phone system would need accurate speech recognition and then be able to infer the meaning of that statement so that it could direct the caller to the right department.
With an expert system, you would have to manually input all the possible statements and questions, and the system would still run into trouble when a caller mumbled or spoke with an accent or spoke in another language.
In this case, machine learning would be the better choice. With machine learning, the system would get smarter over time as it created its own patterns. If someone called in and said something like, “I hate my new smart phone and want to return it,” and they were routed to sales and then transferred to customer service, the system would know that the next time someone called and mentioned the word “return,” that call should be routed directly to customer service, not sales.
When you start an AI program, consider which approach is best for your specific use case. If you can draw a decision tree or flow chart to describe a specific task the computer must perform based on limited inputs, then an expert system is probably the best choice. It may be easier to set up and deploy, saving you time, money and the headaches of dealing with more complex systems. If, however, you’re dealing with massive amounts of data and a system that must adapt to changing inputs, then machine learning is probably the best choice.
Some AI experts mix these two approaches. They use an expert system to define some constraints and then use machine learning to experiment with different answers. So you have three choices — an expert system, machine learning or a combination of the two.
Fueling the rise of machine learning and deep learning is the availability of massive amounts of data, often referred to as big data. If you wanted to create an AI program to identify pictures of cats, you could access millions of cat images online. The same is true, or more true, of other types of data. Various organizations have access to vast amounts of data, including charge card transactions, user behaviors on websites, data from online games, published medical studies, satellite images, online maps, census reports, voter records, economic data and machine-generated data (from machines equipped with sensors that report the status of their operation and any problems they detect). So what is the relationship between AI and big data?
This treasure trove of data has given machine learning a huge advantage over symbolic systems. Having a neural network chew on gigabytes of data and report on it is much easier and quicker than having an expert identify and input patterns and reasoning schemas to enable the computer to deliver accurate responses.
In some ways the evolution of machine learning is similar to how online search engines evolved. Early on, users would consult website directories such as Yahoo! to find what they were looking for — directories that were created and maintained by humans. Website owners would submit their sites to Yahoo! and suggest the categories in which to place them. Yahoo! personnel would then vet the sites and add them to the directory or deny the request. The process was time-consuming and labor-intensive, but it worked well when the web had relatively few websites. When the thousands of websites proliferated into millions and then crossed the one billion threshold, the system broke down fairly quickly. Human beings couldn’t work quickly enough to keep the Yahoo! directories current.
In the mid-1990s Yahoo! partnered with a smaller company called Google that had developed a search engine to locate and categorize web pages. Google’s first search engine examined backlinks (pages that linked to a given page) to determine the relevance and authority of the given page and rank it accordingly in its search results. Since then, Google has developed additional algorithms to determine a page’s rank (or relevance); for example, the more users who enter the same search phrase and click the same link, the higher the ranking that page receives. This approach is similar to the way neurons in an artificial neural network strengthen their connections.
The fact that Google is one of the companies most enthusiastic about AI is no coincidence. The entire business has been built on using machines to interpret massive amounts of data. Rosenblatt's preceptrons could look through only a couple grainy images. Now we have processors that are at least a million times faster sorting through massive amounts of data to find content that’s most likely to be relevant to whatever a user searches for.
Deep learning architecture adds even more power, enabling machines to identify patterns in data that just a few decades ago would have been nearly imperceptible. With more layers in the neural network, it can perceive details that would go unnoticed by most humans. These deep learning artificial networks look at so much data and create so many new connections that it’s not even clear how these programs discover the patterns.
A deep learning neural network is like a black box swirling together computation and data to determine what it means to be a cat. No human knows how the network arrives at its decision. Is it the whiskers? Is it the ears? Or is it something about all cats that we humans are unable to see? In a sense, the deep learning network creates its own model for what it means to be a cat, a model that as of right now humans can only copy or read, but not understand or interpret.
In 2012, Google’s DeepMind project did just that. Developers fed 10 million random images from YouTube videos into a network that had over 1 billion neural connections running on 16,000 processors. They didn’t label any of the data. So the network didn’t know what it meant to be a cat, human or a car. Instead the network just looked through the images and came up with its own clusters. It found that many of the videos contained a very similar cluster. To the network this cluster looked like this.

A “cat” from “Building high-level features using large scale unsupervised learning”
Now as a human you might recognize this as the face of a cat. To the neural network this was just a very common something that it saw in many of the videos. In a sense it invented its own interpretation of a cat. A human might go through and tell the network that this is a cat, but this isn’t necessary for the network to find cats in these videos. In fact the network was able to identify a “cat” 74.8% of the time. In a nod to Alan Turing, the Cato Institute’s Julian Sanchez called this the “Purring Test.”
If you decide to start working with AI, accept the fact that your network might be sensing things that humans are unable to perceive. Artificial intelligence is not the same as human intelligence, and even though we may reach the same conclusions, we’re definitely not going through the same process.
In my previous post Artificial Neural Networks, I explain what an artificial neural network (or simply a neural network) is and what it does. I also point out that what enables a neural network to perform its magic is the layering of neurons. A neural network consists of three layers of neurons — an input layer, one or more hidden layers, and an output layer.
The input and output layers are self-explanatory. The input layer receives data from the outside world and passes it to the hidden layer(s) for processing. The output layer receives the processed data from the hidden layer(s) and coveys it in some way to the outside world.
Yet, what goes on in the hidden layer(s) is more mysterious.
Early neural networks lacked a hidden layer. As a result, they were able to solve only linear problems. For example, suppose you needed a neural network to distinguish cats from dogs. A neural network without a hidden layer could perform this task. It could create a linear model like the one shown below and classify all input that characterizes a cat on one side of the line and all input that characterizes a dog on the other.
However, if you had a more complex problem, such as distinguishing different breeds of dogs, this linear neural network would fail the test. You would need several layers to examine the various characteristics of each breed.
Suppose you have a neural network that can identify a dog's breed simply by "looking" at a picture of a dog. A neural network capable of learning to perform this task could be structured in many different ways, but consider the following (admittedly oversimplified) example of a neural network with several layers, each containing 20 neurons (or nodes).
When you feed a picture of a dog into this fictional neural network, the input layer creates a map of the pixels that comprise the image, recording their positions and grayscale values (zero for black, one for white, and between zero and one for different shades of gray). It then passes this map along to the 20 neurons that comprise the first hidden layer.
The 20 neurons in the first hidden layer look for patterns in the map that identify certain features. One neuron may identify the size of the dog; another, its overall shape; another, its eyes; another, its ears; another, its tail; and so forth. The first hidden layer then passes its results along to the 20 neurons in the second hidden layer.
The neurons in the second hidden layer are responsible for associating the patterns found in the first layer with features of the different breeds. The neurons in this layer may assign a percentage to reflect the probability that a certain feature in the image corresponds to different breeds. For example, based solely on the ears in the image, the breed is 20% likely to be a Doberman, 30% likely to be a poodle, and 50% likely to be a Labrador retriever. The second hidden layer passes its results along to the third hidden layer.
The neurons in the third hidden layer compile and analyze the results from the second hidden layer and, based on the collective probabilities of the dog being a certain breed, determine what that breed is most likely to be. This final determination is then delivered to the output layer, which presents the neural network's determination.
While the example I presented focuses on the layers of the neural network and the neurons (nodes) that comprise those layers, the connections between the neurons play a very important role in how the neural network learns and performs its task.
Every neuron in one layer is connected to every neuron in its neighboring layer. In the example I presented, that's 400 connections between each layer. The strength of each connection can be dialed up or down to change the relative importance of input from one neuron to another. For example, each neuron in the first hidden layer can dial up or down its connection with each neuron in the input layer to determine what it needs to focus on in the image, just as you might focus on different parts of an image.
When the neural network is being trained with a set of test data, it is given the answers — it is shown a picture of each breed and labeled with the name of the breed. During this training session, the neural network makes adjustments within the nodes and between the nodes (the connections). As the neural network is fed more and more images of dogs, it fine-tunes its connections and makes other adjustments to improve its accuracy over time.
Again, this example is oversimplified, but it gives you a general idea of how artificial neural networks operate. The key points to keep in mind are that artificial neural networks contain far more connections than they contain neurons, and that they learn by making adjustments within and between neurons.