9450 SW Gemini Drive #32865
Beaverton, Oregon, 97008-7105
I have worked with several organizations over the years helping them implement machine learning, often after failed attempts to do so on their own. It is no surprise that the organizations that succeed generally do everything right and those that fail often do so as a result of making common mistakes. In this post, I present machine learning dos and don’ts to increase your chances of achieving a successful launch of your machine learning initiative.
Before you even start to introduce machine learning to your organization, you need to find a way to connect your organization’s business needs to machine-learning technology. Otherwise, you are likely to put a program in place and assemble a team with the requisite technical expertise only to find them spending all their time just playing around with the technology.
To avoid this common mistake, take the following steps:
Keep in mind that the best technology isn't necessarily machine learning. Your organization may be able to answer most questions and solve most problems and gain valuable insights with the use of a data warehouse and good business intelligence (BI) software. It may not need a dedicated machine-learning team.
Machine learning often involves supervised learning — feeding the machine labeled data, so the machine can learn the connection between the labels and the data inputs. A common mistake is to mix some of the training data into the test data, which is often tempting when the availability of relevant data is limited. To avoid this mistake, before you engage in supervised learning, create two separate data sets:
If, after training the machine, you mix some of your training data in with your test data, you won't have a clear picture of how well the machine performed on the test. It would be like giving students a sheet of paper with some of the test questions and their correct answers just before they take the test. The test results wouldn't accurately represent what they had learned or where they were struggling.
Algorithms and functions are the engines that drive machine learning, and data is the fuel. Although the machine does the learning and ultimately creates the model that the computer follows to perform the desired task, it is up to you to construct a “brain” that enables the learning process. The building blocks you have to work with are algorithms and functions:
When you are building a machine that can learn, you need to be familiar with a wide variety of algorithms and functions, so you will know which ones to choose and how to arrange them.
After training a machine, you may be tempted to show it off — to demonstrate that your model can actually do something useful and perhaps even amazing. You collect your test data and schedule a presentation to demonstrate the power and precision of your new machine-learning model.
Whoa! This irrational exuberance can end in disaster, maybe not during the presentation but afterward, when someone in your audience uses the model and it misses the mark.
You can avoid the potential embarrassment by running your new model on test data first, so the machine can adjust the model, if necessary, to improve its accuracy. Several rounds of testing (with different test data) and adjustments may be required before your model is ready for prime time.
Of course, there are other pitfalls that you would be wise to avoid when starting out with machine learning, but by steering clear of the common pitfalls covered in this post, you will be far ahead of the game!
In my previous article Artificial Neural Networks Regression and Classification, I introduced the three types of problems that machine learning is generally used to solve:
In that article, I focus on solving classification and regression problems. In this article, I turn my attention to neural network clustering problems — problems that can be solved by identifying common patterns among inputs.
Clustering has numerous applications in a wide variety of fields. Here are a few examples of how clustering may be used:
Unlike classification and regression problems, which employ supervised learning, clustering problems rely on unsupervised learning. With supervised learning, you have clearly labeled data or categories that you are trying to match inputs to. For example, you may want to classify homes by price or classify transactions as fraudulent or honest.
Unfortunately, supervised learning is not always an option. For example, if you do not have clearly labeled data or know the categories into which you want to sort the data inputs, you cannot engage your artificial neural network in supervised learning. In other applications, you may not be interested in classifying your data into categories created by humans; instead, you want to see how your neural network clusters the data to call your attention to patterns you may never have thought to look for.
In such cases, unsupervised learning is the better choice. With unsupervised learning, you let the neural network cluster your data into different groups.
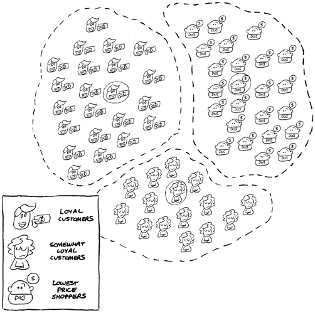
One of the more interesting applications of clustering is its use by large retailers to decide whom to invite to their loyalty programs or when to offer promotions. With unsupervised learning, the machine may identify three clusters of customers — loyal, somewhat loyal, and not loyal. (The not loyal customers always buy from whichever retailer offers the lowest price.) Knowing these clusters, the large retailers create strategies to try and elevate somewhat loyal customers to loyal customers. Or they could invite their loyal customers to participate in special promotions.
Other companies use clustering to decide where to place new stores. For example, a seller of athletic footwear may feed demographic and sales data into an artificial neural network to find locations that have the highest concentration of active runners or locations where customers allocate a higher percentage of their income to outdoor recreation.
When you decide to use machine learning to solve a problem, what is most important is that you choose the right approach for the problem you are trying to solve. Classification is great when you know what you are looking for and can teach the machine the relationship between inputs and labels or between independent variables and a dependent variable. Clustering is a more powerful tool for gaining insight — for seeing things in a different way, a way you may never have considered or when you have a high volume of unlabeled data you want to analyze. After all, there is much more unlabeled (unstructured) data available than there is labeled (structured) data.
When you’re trying to decide which approach to take — classification, regression, or clustering — first ask yourself what problem you’re trying to solve or what question you need to answer. Then ask yourself whether the problem or question is something that can best be addressed with classification, regression, or clustering. Finally, ask yourself whether the data you have is labeled or unlabeled. By answering these questions, you should have a clearer idea of which approach to take: classification or regression (with supervised learning) or clustering (with unsupervised learning).
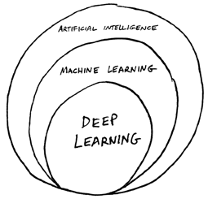
In a previous article What Is Machine Learning? I define machine learning as "the science of getting computers to perform tasks they weren't specifically programmed to do." So what is Deep Learning? Deep learning is a subset of machine learning (ML), which is a subset of artificial intelligence (AI):

In 1958 Cornell professor Frank Rosenblatt created an early version of an artificial neural network composed of interconnected perceptrons. Like the nodes in modern artificial neural networks, a perceptron takes in binary inputs and performs a calculation on those inputs to produce an output, as presented below. Note that with a perceptron both the inputs and outputs are binary — for example, zero/one, on/off, in/out.
Rosenblatt's machine, the Mark I Perceptron, had small cameras and was designed to learn how to tell the difference between two images. Unfortunately, it took thousands of tries, and even then the Mark I had difficulty distinguishing even basic images. In other words, the Mark I Perceptron wasn't a very good student. It could not develop a skill that is relatively easy for humans to learn.
The Mark I Perceptron had a couple flaws — it had only one layer of perceptrons, and the perceptrons were equipped with binary functions. As a result, this artificial neural network could solve only linear problems and had no easy and effective way to adjust the strength of the connections between neurons, which is required for learning to take place.
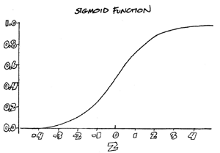
These problems were solved primarily by the introduction of hidden layers in the mid-1980s by Carnegie Mellon professor Geoff Hinton and by replacing binary functions with the sigmoid function, which increased the variation in outputs while limiting those variations between zero and one.
These additions enabled the artificial neural network to tackle much more complicated challenges. However, these early artificial neural networks continued to struggle; they were slow, having to review a problem several times before becoming "smart" enough to solve it.
Later, in the 1990s, Hinton started working in a new field called deep learning — an approach that added many more hidden layers between the input and output layers of the neural network.
The hidden layers of a hidden network function like a black box, swirling together computation and data to find answers and solutions. No human knows how the network arrives at its decision. For example, in 2012, Google’s DeepMind project wanted to see how a deep learning neural network might perceive video data. Developers fed 10 million random images from YouTube videos into a network that had over 1 billion neural connections running on 16,000 processors. They didn’t label any of the data. So the network didn’t know what it meant to be a cat, a human being, or a car. Instead, the network just looked through the images and came up with its own clusters.
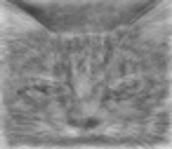
It found that many of the videos contained a very similar cluster. To the network this cluster looked like this.
Now as a human being you might recognize this as the face of a cat, but to the neural network this was just a very common pattern that it recognized in many of the videos. In a sense it invented its own interpretation of a cat. After performing this exercise, the network was able to identify a cat in an image 74.8% of the time.
While it is certainly intriguing to see an artificial neural network recognize objects without ever being trained to do so, the real mystery is how the network accomplishes such a feat. We know that the machine adjusts strengths of the connections between neurons, but we cannot describe the "thought processes" in a way that supports any of the conclusions the machine draws.
The black box nature of hidden layers is important to keep in mind when designing artificial neural networks, because you may be "flying blind" when you're developing your initial design. Success depends a great deal on taking an empirical approach — trying different arrangements of neurons, starting with different weights and biases, trying different activation functions, and then looking at the results and making adjustments.
In one of my previous articles, How Machines Learn, I present a basic recipe for machine learning, including the essential ingredients and the step-by-step instructions for making it happen. One of the main ingredients is data, and sometimes lots of it. Just as people need data input to learn anything, so do machines. The key difference with machines is that the input needs to be digitized.
Another big difference is that machines are designed and built by humans, typically to perform specific tasks, such as driving a car, estimating a home's market value, recommending products, and so on. To a great degree, the purpose of the machine learning product and the data the machine needs to fulfill that purpose drive the design of the machine. The human developer needs to choose a statistical model that predicts values as close as possible to the ones observed in the data. This is called fitting model to data.
The purpose of fitting the model to the data is to improve the model's accuracy in the task it is designed to perform. Think of it as the difference between a suit off the rack and a tailored suit. With a suit off the rack, you usually have too much fabric in some areas and not enough in others. A tailored suit, on the other hand, is adjusted to match the contours of the wearer's body. Fitting the model to the data involves making adjustments to the model to optimize the accuracy of the output.
With machine learning, fitting the model involves setting hyperparameters — conditions or boundaries, defined by a human, within which the machine learning is to take place. Hyperparameters include the choice and arrangement of machine learning algorithm(s), the number of hidden layers in an artificial neural network, and the selection of different predictors.
The fine-tuning of hyperparameters is a big part of what data scientists do. They build models, run experiments on small datasets, analyze the results, and tweak the hyperparameters to get more accurate results.
Poor performance of a model can often be attributed to underfitting or overfitting:
The ultimate goal of the tuning process is to minimize bias and variance.
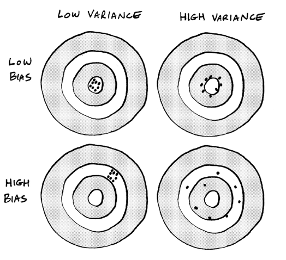
Consider a real-world example. Imagine you work for a website like Zillow that estimates home values based on the values of comparable homes. To keep the model simple, you create a basic regression chart that shows the relationship between the location of a house, its square footage, and its price. Your chart shows that big houses in nice areas have higher values. This model benefits from being intuitive. You would think that a big house in a nice area is more expensive than a small house in a rundown neighborhood. The model is also easy to visualize.
Unfortunately, this model isn't very flexible. A big house could be poorly maintained. It might have a lousy floor plan or be built on a floodplain. These factors would impact the home's value but they wouldn't be considered in the model. Because it’s not accounting for enough data, this model is likely to make inaccurate predictions; it suffers from underfitting, resulting in high bias.
To reduce the bias, you add complexity to the model in the form of additional predictors:
As you add predictors, the machine makes the model more flexible, but also more complex and difficult to manage. You solved the bias problem, but now the model has too much variance due to overfitting. As a result, the machine's predictions are off the mark for too many homes in the area.
To avoid underfitting and overfitting, you want to capture more signal and less noise:
In our Zillow example, you can capture more signal by choosing better predictors, such as number of bedrooms, number of bathrooms, quality of the school system, and so on, while eliminating less useful predictors, such as attic or basement storage. You really would need to examine the data closely to determine the factors that truly impact a home's value. In short, as the human developer, you would really need to put some careful thought into it.
In my previous article How Machines Learn, I list the essential ingredients needed for the ways machines learn. Here is the basic 5-step process that enables machines to learn. I also mention two types of machine learning — supervised and unsupervised. In this post, I do a deeper dive into these two types of machine learning, along with a third — reinforcement learning. First, let's take a look at how people learn.
People learn in all sorts of ways — through reading, listening, observing, sensing, feeling, playing, interacting, comparing, experiencing, reasoning, teaching, trial and error, and so on. Psychic Edgar Cayce claimed he learned how to spell by sleeping with his spelling book under his pillow. And all of those learning methods I just mentioned merely scratch the surface. Scientists are still trying to figure out how the brain works and identify the many ways the brain functions to learn new things.
Imagine you want to learn how to play checkers. You could do this in several different ways. You could hire a tutor, who would introduce you to the game, teach you how to move the checkers, and show you some winning strategies. You could practice by playing against the tutor, who would supervise your moves and perhaps correct you when you make a foolish mistake. As you increase your mastery of the game, you would then be able to play without supervision and even develop your own strategies.
Another option would be to watch people play checkers. By closely observing how others play the game, you could probably figure out how to move the checkers, how to jump an opponent's checkers, how to earn a crown, and so forth. You would probably also start to identify different strategies for winning.
You might even try a combination of these two approaches. A tutor would bring you up to speed on the basics — how to set up the board, move the checkers, jump an opponent's checkers, earn a crown, and so forth — and then you'd observe other people playing. You'd have a high-level overview of the game, but you'd rely on your own observations to learn new strategies and improve your game.
The three ways to learn to play checkers are very similar to how machines often learn:
Reinforcement learning is a technique that involves rewarding the machine for its performance. Reinforcement learning has its roots in operant conditioning — the principle that behavior followed by pleasant consequences is likely to be repeated, and behavior followed by unpleasant consequences is less likely to be repeated. With reinforcement learning, a reward is associated with a certain action or occurrence, and an environment is created in which the machine attempts to maximize its cumulative reward.
In 2013 Google's DeepMind project produced an application of reinforcement learning its developers called Q-learning. In Q-learning, you have a set environments or states typically represented by the letter "S," possible actions that can respond to the states represented by the letter "A," and quality of performance represented by the letter "Q."
Suppose you have an Atari game like Space Invaders that requires you to blast aliens with your laser cannon as they descend from the sky. To help the computer learn how to play, you might have S represent the number of aliens descending and the speed of descent and A represent actions the computer takes to shoot aliens out of the sky, thus improving Q, which represents the score of the game. Each time the computer successfully shoots down an alien, it's rewarded with an increase in Q. The machine plays the game repeatedly and, attempting to maximize Q, becomes much more adept at shooting down aliens.
Reinforcement learning, specifically Q-Learning, enables machines to quickly grow beyond our understanding. It can help you skip the steps required for collecting data and then feeding the machine training data and test data. The machine essentially creates its own data as it engages in iterative trial and error.
While supervised, unsupervised, semi-supervised, and reinforcement learning are the primary ways machines learn, stay tuned for more to come. Experts in artificial intelligence (AI) are constantly working on developing new approaches to machine learning and understanding how to combine different techniques.
You have data, and you have questions to answer and problems to solve. How do you go about using your data to answer those questions and solve those problems? Due to the power and popularity of big data, machine learning (ML), and artificial intelligence (AI), many organizations leap to the conclusion that choosing machine learning is the best approach. However, older, less sophisticated options may deliver better results, depending on the purpose. Sometimes, a spreadsheet or database program is all you need.
The following is a list of options along with suggestions of when each option may be most appropriate for any given data product:
When you're trying to decide between machine learning and an expert system, ask the following question: Does the task require sequential reasoning or pattern matching? If it requires sequential reasoning and the task can be mapped out, go with an expert system. If it requires pattern matching, either to make a prediction or to help uncover hidden meaning in the data, machine learning is probably best.
Prior to deciding which approach is the best match for the problem you're trying to solve or the question you're trying to answer, consult your data science team. Other people on the team may be able to offer valuable insights based on their unique perspectives and training. Encourage your team to ask questions, so they begin to develop an exploratory mindset. Team members should challenge one another's ideas and recommendations, so, together, the team can choose the best approach. (During this process, you may even discover that the question or problem you have identified is not the one you should be seeking to answer or solve. Instead, there may be a more compelling path to explore.)
Keep in mind that two distinctly different approaches may be effective in answering the question or solving the problem, and that a combination of approaches (an ensemble) may be the best approach. If two different approaches seem to be equally effective, opt for the easiest, most cost-effective option.
What is important is that you and your data science team carefully consider the different approaches before starting your work. Choosing the right approach and the right tools will make your job that much easier and deliver superior results.
In a previous article What Is Machine Learning? I present a brief history of machine learning and discuss how machine learning developed as a way to overcome certain limitations in the early days of artificial intelligence. Without the ability to learn, early developers could make machines do only what they were told or programmed to do. Machine learning expands their capabilities beyond what they are merely programmed to do.
When people first encounter the concept of machine learning, they often wonder how machines learn? We are accustomed to working with software that is written to program machines to interact with humans via keyboard, mouse, display screen, microphone, and speakers. We may have even noticed some mock forms of machine learning, such as programs that rearrange menu options based on the frequency with which the user chooses certain commands. However, learning how to distinguish between objects and adapt to one's environment involves complexity of another scale entirely, which makes people wonder, "How can machines possibly do that?"
Programming involves writing code that tells a machine, in a digital language, how to perform specific tasks. All you need is a machine that understands the programming language and instructions (software) written in that language. Machine learning requires a more complex combination of ingredients:
The machine learning process is complicated and varies considerably based on the task and the type of learning (supervised or unsupervised), but it generally follows these steps:
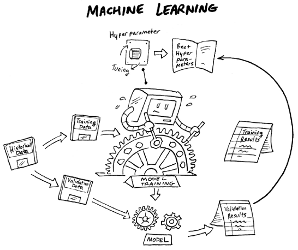
1. A human participant sets the hyperparameters, which involves deciding on the number and arrangement of artificial neurons, choosing a machine learning algorithm, and so on.
2. The human participant feeds the machine input data. The data type varies depending on whether the machine is engaging in supervised or unsupervised learning:
3. Using the algorithm, the machine performs calculations on the inputs, adjusting the parameters as necessary:
4. As it processes the inputs (or input-output pairs), the machine creates a model that consists of the algorithm and parameters required to calculate outputs based on the given inputs (supervised learning) or figure out which group an input belongs to (unsupervised learning).
5. When you feed the machine inputs, it has learned how to process those inputs to deliver the correct (or most likely to be correct) outputs.
Learning does not necessarily stop at Step 5. It may continue for as long as the model is in use, fine-tuning itself to produce more accurate outputs. For example, if you have a model that distinguishes spam from not-spam, every time a user moves a message from the Spam folder to the Inbox or vice versa, the machine adjusts the model in response to the correction.
Suppose you have the following input-output pairs showing a direct correlation between the size of houses and their prices:
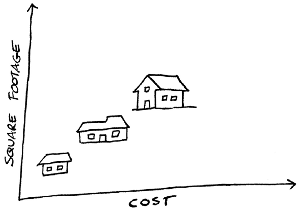
1,000 square feet = $50,000
1,500 square feet = $75,000
2,000 square feet = $100,000
2,500 square feet = $125,000
If you were to graph these values, you'd get a straight line, and this line could be described using the linear equation (algorithm) y = mx + b, where x is square footage (input), y is price (output), m is the slope of the line and b is the point at which the line crosses the y axis. In this algorithm, m and b are the parameters. Given the inputs and outputs, the slope of the line (m) is 1 and the line crosses the y-axis at 0 (zero). So the machine's initial model would be y = 1x + 0.
Now suppose the machine were fed an input-output pair of 3,000 square feet = $175,000. If you were to plot that point on the graph, you would see that it is not on the line, so the machine's model is not 100% accurate.
To fix the model, the machine can adjust one or both parameters. It can change the slope of the line (m) or the y-intercept (b) or change both. That's how the machine "learns" with supervised learning.
In my previous articles What Are Machine Learning Algorithms and Choosing the Right Machine Learning Algorithm, I describe several commonly used machine learning algorithms and provide guidance for choosing the right one based on the desired use case and other factors.
However, you are not limited to using only one machine learning algorithm in a given application. You also have the option of combining machine learning algorithms through various techniques referred to collectively as ensemble modeling. One option is to combine the outcomes of two or more algorithms. Another option is to create different data samples, feed each data sample to a machine learning algorithm, and then combine the two outputs to make a final decision. In this post, I explain the three approaches to ensemble modeling — bagging, boosting, and stacking.
Bagging involves combining the outputs from two or more algorithms with the goal of improving the accuracy of the final output. Here's how it works:

The bagging approach results in reduction of variance, which in turn may improve the overall accuracy of the output in comparison to using a single tree.

Boosting involves one or more techniques to help algorithms accurately classify inputs that are difficult to classify correctly. One technique involves combining algorithms to increase their collective power. Another technique involves assigning the characteristics of challenging data objects greater weights or levels of importance. The process runs iteratively, so that the machine learns different classifiers by re-weighting the data such that the newer classifiers focus more on the characteristics of the data objects that were previously misclassified.
Like bagging, boosting results in reduction of variance, but boosting can be sensitive to outliers — inputs that lie outside the range of the other inputs. Adjusting for the outliers may actually reduce its accuracy.
Stacking involves using two or more different machine learning algorithms (or different versions of the same algorithm) and combining their outputs using another meta-learner to improve the classification accuracy.
The team that won the Netflix prize used a form of stacking called feature-weighted linear stacking. They created several different predictive models and then stacked them on top of each other. So you could stack K-nearest neighbor on top of Naïve Bayes. Each one might add just .01% more accuracy, but over time a small increase in accuracy can result in significant improvement. Some winners of this machine learning competition stacked 30 algorithms or more!
Think of ensemble modeling as the machine learning version of "Two heads are better than one." Each of the techniques I describe in this post involve combining two or more algorithms to increase the total accuracy of the model. You can also think of ensemble modeling as machine learning's way of adding brain cells — by strategically combining algorithms, you essentially raise the machine's IQ. Keep in mind, however, that you need to give careful thought to how you combine the algorithms. Otherwise, you may end up actually lowering the machine's prediction abilities.
In my previous article The Different Ways Machines Learn, I described the four common approaches to machine learning:
Within these different approaches, developers use a variety of machine-learning algorithms (An algorithm is a set of rules for solving a problem in a fixed number of steps). So what are machine learning algorithms? Common machine-learning algorithms include decision trees, K-nearest neighbor, K-means clustering, regression analysis, and naïve Bayes, all of which I describe in this post.
A decision tree is a flow chart for choosing a course of action or drawing a conclusion. They are often used to solve binary classification problems; for example, whether to approve or reject a loan application.

Suppose you wanted to create a decision tree to predict whether or not someone will go to the beach. To create your decision tree, you might start with Sky, which branches off into three possible conditions: Sunny, Rainy or Overcast. Each of these conditions may or may not branch off to additional conditions; for example, Sunny branches off to “85° or Above” and “Below 85°,” and Overcast branches off to “Weekend” and “Weekday.” Making a decision is a simple matter of following the branches of the tree; for example, if the day is sunny and above 85°, Joe goes to the beach, but if the sky is overcast and it’s a weekday, Joe doesn’t go to the beach.
Decision trees are useful for binary classification — when there are only two choices, such as Joe goes or doesn’t go to the beach, a loan application is approved or rejected, or a transaction is fraudulent or not.
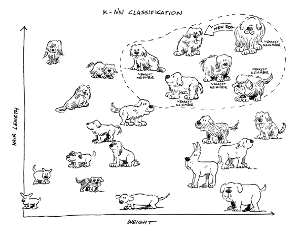
The K-nearest neighbor algorithm classifies data based on similarities, making it very useful for multi-class classification. With K-nearest neighbor, you essentially chart points on a graph that represent known things with certain characteristics, and then identify groups of points that are nearest to each other (the nearest neighbors). The K represents the number of nearest neighbors. K = 1 means only 1 nearest neighbor. K = 2 means two nearest neighbors. The higher the K value, the broader the category or class.
Another very common machine learning algorithm is K-means clustering, which is often confused with K-nearest neighbor (KNN). However, while K-nearest neighbor is a supervised machine learning algorithm, K- means clustering is an unsupervised machine learning algorithm. Another difference is that the K in K-nearest neighbor represents the number of nearest neighbors used to classify inputs, whereas the K in K-means clustering represents the number of groups you want the machine to create.
For example, suppose you have dozens of pictures of dogs, and you want the machine to create three groups with similar dogs in each group. With unsupervised learning, you don’t create the groups — the machine does that. All you do is tell the machine to create three groups, so K = 3.
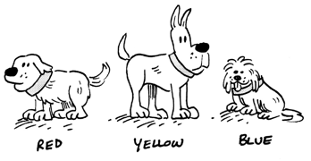
It just so happens that all the dogs have collars and each collar is either red, yellow, or blue. The machine focuses on the collars and creates three groups — one for each color — and assigns dogs to each of those groups based on the color of their collars.
Regression analysis looks at the relationship between predictors and outcomes in an attempt to make predictions of future outcomes. (Predictors are also referred to as input variables, independent variables, or even regressors.) With machine learning (supervised learning to be precise), you feed the machine training data that contains a small collection of predictors and their associated known outcomes, and the machine develops a model that describes the relationship between predictors and outcomes.
Linear regression is one of the most common types of machine learning regression algorithms. With linear regression you want to create a straight line that shows the relationship between predictors and outcomes. Ideally you want to see all your different data points closely gathered around a straight line, but not necessarily touching the line or on the line.
For example, you could use linear regression to determine the relationship between the outdoor temperature and ice cream sales.
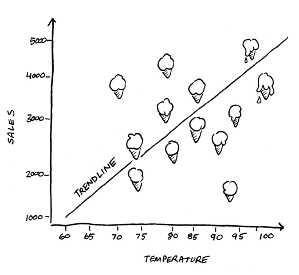
You can see a very clear trendline in this scatterplot diagram; the higher the temperature the greater the ice cream sales. You can also see a few outliers — data points that are far away from the trendline. This could be due to a local festival or because someone had scheduled a birthday gathering at the shop that day. Having a lot of outliers makes it much more difficult to use linear regression to predict ice cream sales.
Naïve Bayes differs considerably from the machine learning algorithms covered so far. Instead of looking for patterns among predictors, naïve Bayes uses conditional probability to determine the likelihood of something belonging to a certain class based on each predictor independent of the others. It's called naïve because it naïvely assumes that the predictors aren't related.
For example, you could use a naïve Bayes algorithm, to differentiate three classes of dog breeds — terrier, hound, and sport dogs. Each class has three predictors — hair length, height, and weight. The algorithm does something called class predictor probability. For each predictor, it determines the probability of a dog belonging to a certain class.
For example, the algorithm first checks the dog's hair length and determines that there's a 40% chance the dog is a terrier, a 10% chance it's a hound and a 50% chance it's a sport dog. Then, it checks the dog's height and determines that there's a 20% chance the dog is a terrier, a 10% chance it's the hound and a 70% chance it's a sport dog. Finally, it checks the dog's weight and figures that there's a 10% chance that the dog is a terrier, a 5% chance that it's a hound and an 85% chance that it's a sport dog. It totals the probabilities, perhaps giving more weight to some than others, and, based on that total, chooses the class in which the dog is most likely to belong.
Naïve Bayes gets more complicated, but this is generally how it works.
One of the critical steps in any attempt at machine learning is to choose the right algorithm or combination of algorithms for the job, but I will reserve that topic for future posts.
In my previous article, Machine Learning Algorithms, I explain what machine-learning algorithms are and describe the following commonly used algorithms:
Based on the descriptions of the machine learning algorithms I presented in that post, you could already start to figure out which algorithm would be best for answering a certain type of question or solving a certain type of problem. In this article, I provide some additional guidance.
Your choice of algorithm generally depends on what you want the algorithm to do:
When choosing an algorithm, consider a more empirical (experimental) approach. After narrowing your choice to two or more algorithms, you can train and test the machine using each algorithm with the data you have and see which one delivers the most accurate results. For example, if you're looking at a classification problem, you can run your training data on K-nearest neighbor and Naïve Bayes and then run your test data through each of them to see which one is best able to accurately predict which class a particular unclassified entity belongs to.
There is a more formal method for choosing a machine-learning algorithm, as presented in the following sections.
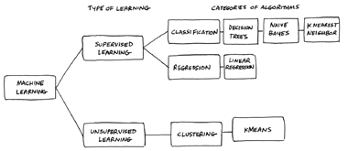
The first step is to figure out the nature of the problem you are trying to solve via machine learning. Categorize the problem by both input and output:
1. Categorize the problem by input:
2. Categorize the problem by output:
The data you have also informs your choice of machine-learning algorithm:
Conditions beyond your control may influence your choice of machine-learning algorithm. For example:
Also, ask the following questions:
The final step involves making your choice. The following table provides a list of algorithms along with specific use cases in which each application may be most suitable, as well as the pros and cons of each algorithm.
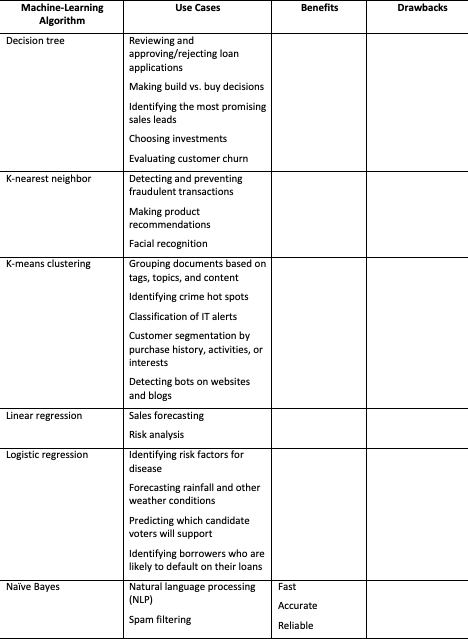
Remember, prior to building a machine learning model, it is always wise to consult others on your data science team, particularly your resident data scientist, if you are fortunate enough to have one. Choosing a machine learning algorithm is a combination of art and science, so you’re likely to benefit by having someone look at the problem from another perspective.