9450 SW Gemini Drive #32865
Beaverton, Oregon, 97008-7105
In my previous post, "Data Science Evidence," I encourage data science teams to be skeptical of any claims or evidence that supports those claims, and I provide several techniques for challenging claims and evidence.
However, missing data can be just as misleading as wrong data, if not more so. One of the big problems with missing data is that people can't see what's not there. When you have data, you can check for errors and validate it. With missing data, you have nothing to check. You may not even think to ask about it or look for it.
For example, suppose you see the following graph with the headline: “Major Heat Wave in Atlanta!"
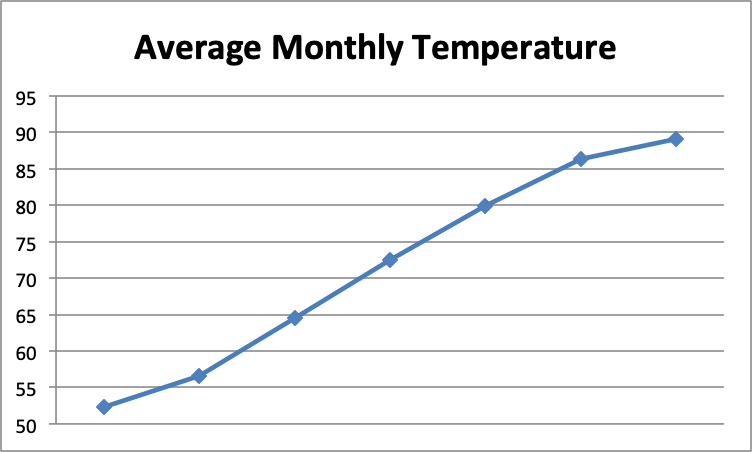
Your initial reaction might be that temperatures are rising precipitously in Atlanta and something must be done to reverse this dangerous trend. What's missing from this graph? The months along the horizontal axis: January through July. Of course monthly temperatures are going to rise dramatically over the spring and summer months!
I once worked for an organization that was trying to figure out why more men than women were participating in their medication trials. A report from the company's labs showed that 60 percent of its study participants were men compared to only 40 percent who were women. The data science team was assigned the job of finding out why men are more likely to participate in the company's medication studies than women.
When team members received this report, they asked, “What significant information are we missing?” “What does it mean that men are more likely than women to participate?” Does that mean that more men applied or that equal numbers of men and women applied but that a greater number of men were accepted? Or does it mean that equal numbers of men and women applied and were accepted but more men actually participated?
This additional data would shift the team's exploration in different directions. If more men applied, the next question would be "Why are men more likely than women to apply for our medication studies?" If equal numbers of men and women applied but more men were accepted, the next question would be "Why are more men being accepted?" or "Why are more women being rejected?" If equal numbers of men and women applied and were accepted but more men actually participated, the next question would be "Why are men more likely to follow through?" As you can see, the missing data has a significant impact on where the team directs its future exploration.
When you encounter a scenario like this, consider both what data might be missing and why it might be missing:
This last question turned out to be significant. The benefit to having more women participate in the company's studies is that young women are more likely to be on prescription medication, which would make the studies more comprehensive. The medication studies would be able to test for a greater number of drug interactions. The flip side is that many women couldn't participate because they were taking a prescription medication that prohibited them from participating in the study. The statistic could then be rephrased as "60 percent of those who are allowed to participate in our medication studies are men.” This tells an entirely different story.
Data science teams need to remain vigilant regarding missing information. If a claim seems too good or too bad to be true, the team needs to question it and ask, "What's the rest of the story? What's missing? What's been omitted, intentionally or not?" The team also should always be asking, "Do we have all the relevant data?"
Data drives the data science team's exploration and discovery, so the team must be on the constant lookout for bad data, which can lead the team astray or result in erroneous conclusions. In this post, I present several ways to challenge the data science evidence the team is provided to ensure that the team is working with accurate information and to generate addition questions that may lead to valuable discoveries.
Many organizations rely on what they believe to be facts in their daily operations. Questioning these "facts" may be taboo for the rest of the organization, but they are fair game to the data science team. After all, one of the data science team's key obligations is to challenge assumptions.
Whenever your data science team encounters a "fact," it should challenge the claim by asking the following questions:
When you're working on the data science team, you'll see all kinds of well-established "facts." The source of these "facts" are numerous and varied: intuition, personal experiences, examples, expert opinions, analogies, tradition, white-papers, and so on. Part of your job as a member of the data science team is to question these "facts," not reject them outright. As you explore, you may find evidence to support the "fact," evidence to refute it, a lack of evidence, or a mix of inconclusive evidence. Keep an open mind as you gather and examine the evidence.
It's easy to say that correlation doesn't imply causation — just because one event follows another doesn't mean that the first event caused the second — but distinguishing the difference between correlation and causation is not always easy. Sometimes, it is easy. If you bump your head, and it hurts, you know the pain was caused from bumping your head.
However, sometimes, it is not so easy. For example, when a doctor noticed that many children were developing autism after receiving a vaccination to protect against measles, mumps, and rubella, he and some of his colleagues found it very tempting to suggest a possible cause-effect relationship between the vaccination and autism. Later research disproved any connection. It just so happens that children tend to develop autism about the same time they are scheduled to receive this vaccination.
Whenever your data science team encounters an alleged cause-effect relationship, it should look for the following:
While true that "numbers don't lie," people frequently use numbers, specifically statistics, to lie or mislead. A classic example is in advertisement, where 80 percent of dentists recommend a specific toothpaste. The truth is that in many of these studies, dentists were allowed to choose several brands from a list of options, so other brands may have been just as popular, or even more popular, than the advertised brand.
When your team encounters statistics or a claim based on statistics, it needs to dig into those numbers and identify the source of the information and how the numbers were obtained. Don't accept statistics at face value.
Remember that a data science team can only be as good as the data (evidence) it has. Many teams get caught up in capturing more and more data at the expense of overlooking the data's quality. Teams need to continuously evaluate the evidence. The techniques described in this post are a great start.
Bottom line, the data science team needs to be skeptical. When presented with a claim or evidence to back up a claim, it needs to challenge it. An old Russian proverb advises "Trust but verify." I go a step further to recommend that you not trust at all — be suspicious of all claims and evidence that your data science team encounters.
Data science teams capture, store, and analyze data to extract valuable information and insight. In recent posts, I focused on capturing and storing three types of data — structured, semi-structured, and unstructured — and I encouraged readers to avoid the common trap of allowing big data to become big garbage.
In this article, I shift focus to analysis — using statistics, mathematics, and other analytical tools to extract meaning and insight from data. Although specific statistical methods vary considerably, they can be broken down into the following five categories:
In the following sections, I describe each of these five approaches to statistical analysis in greater detail and provide a word of caution at the end.
Descriptive statistic is a quantitative summary of a collection of data. Descriptive statistics include the following:
Descriptive analytics are great for story-telling, proving a point, and hiding facts, which is why this approach is commonly used in political campaigns. One candidate may claim, “Over the last four years, average salaries have risen $5,000,” while her opponent claims, “Compared to four years ago, a typical middle class family now earns $10,000 less.” Who’s telling the truth? Maybe they both are. Opposing candidates often draw on the same data and use descriptive analytics to present it ways that support whatever point they’re trying to make.
In this example, the first candidate uses the mean to show that the average family earned about $5,000 more. The opposing candidate used the median(typical middle class family, not including poor or rich families) to make the case that a certain segment of the population was now earning less than they did four years ago. Both candidates are right, while neither candidate presents the entire truth.
Probability is the likelihood that something will happen. If you flip a coin, the probability is 50 percent it will land heads or tails. If you roll a six-sided die, you have a 1/6 or about a 17 percent probability of rolling any given number from one to six. Probability can also be used to gauge the likelihood of a coin landing heads twice in a row or rolling a specific number on a die twice in a row.
In data science, calculating probabilities can produce valuable insights. I once worked with a biotech company that was trying to determine the probability of people participating in a clinical trial, which is impacted by a number of factors. If participants are required to fast the night before, they’re about 30 percent less likely to participate. If a needle or a blood test is required, they’re about 20 percent less likely to participate. These results enabled the company to consider alternatives, such as replacing the blood test with a saliva test. However, they then had to analyze the possible impact on the results of the study if they made that change.
Data science is like that. The answer to one question may lead to other questions requiring additional analyses. When working on a data science team, be prepared to ask follow-up questions and harness the power of data to answer them.
Correlation is another very interesting area in data science. Many companies use correlation to analyze customer data and make targeted product recommendations. For example, Netflix looks at all the movies and TV shows you watched to recommend movies that are likely to appeal to you. Likewise, Amazon analyzes your purchase and search histories to recommend products you might like.
Correlations are commonly broken down into two categories:
Data science teams look for correlations, as measured by the correlation coefficient— a value between –1 and 1 that indicates how closely related two variables are. Zero (0) indicates no correlation, 1 indicates a strong positive correlation, and –1 indicates a strong negative correlation.
Correlation is also useful for testing assumptions. For example, if a business assumes that customers who buy the most are the most satisfied, it could run correlation analysis to compare spending and satisfaction in order to prove or disprove that assumption.
Causation is correlation with a twist. The twist is that the two variables being studied are related through cause and effect. Keep in mind, however, that correlation does not prove causation. Just because it rains every time I forget to close my car windows doesn’t mean that forgetting to close the windows causes it to rain.
For example, when my parents got older, they moved to a retirement community in southern Florida. Statistically, their community is one of the most dangerous places on earth. People are constantly being hospitalized or buried. If you looked at the correlation between the community and rates of hospitalizations and deaths, you’d think they lived in a war zone. But the actual correlation is between age and rates of hospitalizations and deaths. The community is very safe.
If causation is proven, it can come in very handy for answering “Why” questions. Why do sales drop off in July? Why do people who live in a certain location have a greater incidence of lung cancer? Why are so many people returning our product? Careful analysis of the right data can answer these and other probing questions.
Perhaps the most fascinating and valuable application of statistical analysis is predictive analytics. Imagine having a crystal ball that enables you to see the future. By peering into that crystal ball, an organization could see the next big thing. It could tell what the competition was going to do before the competition knew. It could spot developing trends and be first to market with hot-selling products.
Think of predictive analytics as weather forecasting. Nobody really knows what the weather will be like the next day, but meteorologists can look at current data and compare it to historical data to make an accurate prediction of what the weather will be several days from today. They combine various types of data, including temperatures, pressures, humidity levels, and wind directions and speeds; analyze the data to spot patterns; correlate the patterns with historical data; and then draw their conclusions.
In the same way, organizations in a variety of sectors can analyze the data they have to spot patterns and trends and make predictions. And with the growing volume of data in the world, these predictions are becoming more and more precise.
Regardless of the approaches you use to analyze your data, be curious and skeptical. Data and the conclusions drawn from that data can be misleading, so challenge assumptions and conclusions. Ask questions, such as “Does this answer or conclusion make sense?” “Did we use the right data?” “What am I missing?” and “What else could this mean?” Use different analytical methods to examine the data from different perspectives. As a data scientist, you need to think like a scientist.