9450 SW Gemini Drive #32865
Beaverton, Oregon, 97008-7105
One of the biggest challenges your data science team is likely to encounter is gaining access to all of the organization’s data. Many organizations have data silos— data repositories managed by different departments and isolated from the rest of the organization.
The term “silo” is borrowed from agriculture. Farmers typically store grain in tall, hollow towers called silos, each of which is an independent structure. Silos typically protect the grain from the weather and isolate different stores of grain, so if one store is contaminated by pests or disease all of the grain isn’t lost. Data silos are similar in that each department’s database is separate; data from one department isn’t mixed with data from another.
Data silos develop for various reasons. Often they result from common practice — for example, human resources (HR) creates its own database, because it can’t imagine anyone else in the organization needing its data or because it needs to ensure that sensitive employee data is secure. Data silos may also arise due to office politics — one team doesn’t want to share its data with another team that it perceives to be a threat to its position in the organization.
If your data science team encounters a data silo, it needs to find a way to access that data. Gaining access to data is one of the primary responsibilities of the project manager on the data science team. After the data analyst identifies the data sets necessary for the team to do its job, the project manager needs to figure out how to gain access to that data.
Although data silos may be useful for protecting sensitive data from malware and from unauthorized access, they also cause a number of problems, including the following:
I once worked for an organization that was trying to migrate all its data to a central data warehouse. They felt that the organization wasn’t getting enough insight from its data. The organization had just gone through a data governance transformation and wanted to govern how the data was controlled in the organization.
When they finally got into their data, they realized how much was locked away in silos that no one knew about. Over many years, each department had created its own processes, schemas, and security procedures. The organization wanted to get value from this data, but that data was stored on different servers across the entire company. To compound the problem, the various departments were reluctant to share their data. It was as if the project manager was asking them to share toothbrushes.
One of the first steps toward becoming a data-driven organization is to break down the data silos:
By breaking down data silos, you give everyone in your organization self-serve access to the data they need to do their jobs better.
If you’re a project manager on a data science team, try to keep the following key points in mind:
Democratizing data involves making it available to personnel throughout an organization and providing them with the tools and training needed to query and analyze that data. In this post, I discuss the potential benefits and drawbacks of data democratization and provide some general guidance for democratizing data.
Nearly every organization that democratizes its data properly reports that the benefits of doing so far outweigh any potential drawbacks. However, organizations do need to address the following concerns:
Traditionally, the IT department has owned the data and was in charge of extracting meaning from it and presenting the information to executives and managers. The development of various technologies, tools, and techniques is driving the movement toward greater democratization of data:
Democratizing data is not a simple matter of providing everyone in the organization unfettered access to all of the organization’s data, especially if the organization stores sensitive data. To democratize data safely and effectively, consider the following guidelines:
If your organization currently places the power of its data in the hands of a few, I hope this article encourages you to strongly consider the possibility of democratizing your organization’s data. By placing the power of data and analytics in the hands of the many, you’re likely to be surprised by the resulting increase in innovation and agility. Your organization will be much better equipped to adapt in a competitive landscape that’s constantly changing.
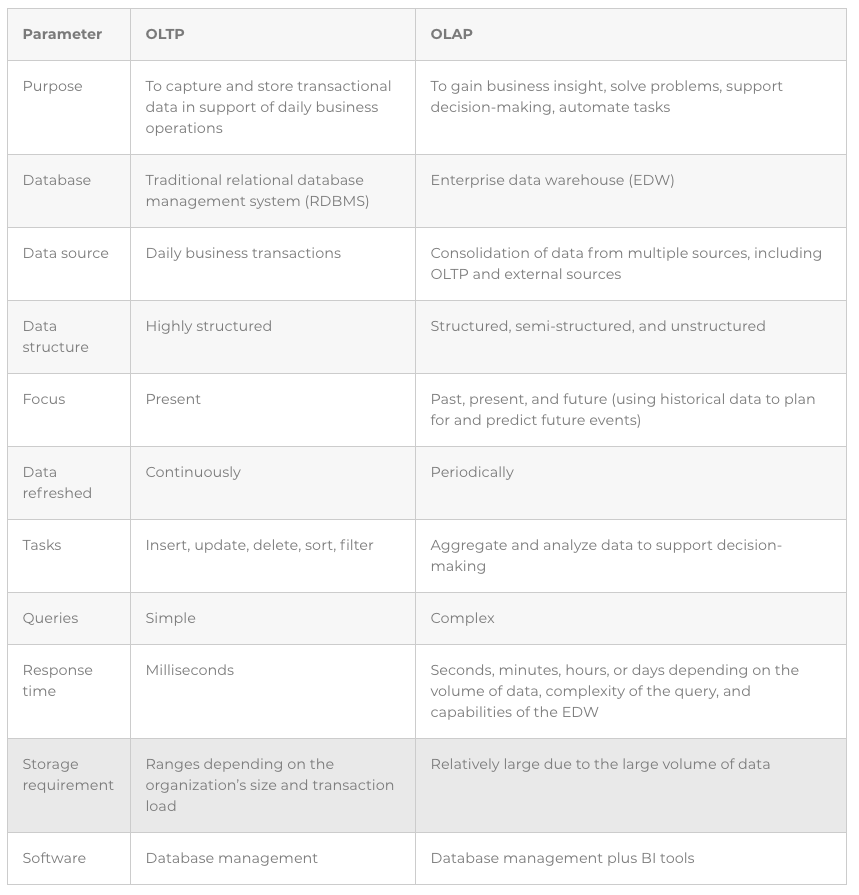
Businesses and other organizations typically have two types of database management systems (DBMSs) — one for online transactional processing (OLTP) and another for online analytical processing (OLAP):
Online transactional processing (OLTP): A type of information system that captures and stores daily operational data; for example, order information, inventory transactions, and customer relationship management (CRM) details. OLTP systems are commonly used for online banking, booking flights or rooms online, ordering products online, and so on.
Online analytical processing (OLAP): A type of information system that supports business intelligence (BI) applications, such as tools for generating reports, visualizing data (with tables, graphs, maps, and so on), and conducting predictive “what if” analyses. OLAP systems are commonly used for planning, solving problems, supporting decision-making, and automating tasks (as with machine learning applications).
Traditional databases are optimized for OLTP, where the emphasis is on capturing transactional data in real time, securing transactional data, maintaining data integrity, and processing queries as quickly as possible. On the other hand, enterprise data warehouses (EDWs) are optimized for OLAP, where the emphasis is on capturing and storing large volumes of historical data, aggregating that data, and mining it for business knowledge and insights to support data-driven decision-making.
The following table highlights the differences between OLTP and OLAP
Suppose you want to sell running shoes online. You hire a database administrator (DBA) who creates dozens of different tables and relationships. You have a table for customer addresses, a table for shoes, a table for shipping options, and so on. The web server uses structured query language (SQL) statements to capture and store the transaction data. When a customer buys a pair of shoes, her address is added to the Customer Address table, the Shoes table is updated to reflect a change in inventory, the customer’s desired shipping method is captured, and so on. You want this database to be fast, accurate, and efficient. This is OLTP.
You also ask your DBA to create a script that uploads each day’s data to your EDW. You have a data analyst create a report to see whether customer addresses are related in any way to the shoes they buy. You find that people in warmer areas are more likely to buy brightly colored shoes. You use this information to change your website, so customers from warmer climates see more brightly colored shoes at the top of the page. This is an example of OLAP. While you don’t need real-time results, you do need to be able to aggregate and visualize data to extract meaning and insight from it.
Most organizations have separate OLTP and OLAP systems, and they copy data from their OLTP system to their OLAP system via a process referred to as extract, transform, and load (ETL):
For more about ETL, see my previous article Grasping Extract, Transform, and Load (ETL) Basics.
Some newer database designs attempt to combine OLTP and OLAP into a single solution, commonly referred to as a translytical database. However, OLTP systems are highly normalized to reduce redundancy, while OLAP reduces the required degree of normalization to achieve optimal performance for analytics.
Normalization is a process of breaking down data into smaller tables to reduce or eliminate the need to repeat fields in different tables. If you have the same field entries in different tables, when you update an entry in one table, you have to update it in the other; failing to do so results in a loss of data integrity. With normalization, when you need to change a field entry, such as a customer’s phone number, you have only one table in which you need to change it.
Because OLTP and OLAP differ in the degree to which data must be structured, combining the two is a major challenge. However, organizations are encountering an increasing need to analyze transactional data in real time, so the benefits of a translytical database model are likely to drive database and data warehousing technology in that direction.
To analyze a body of data, that data must first be loaded into a data warehouse; that is, it must be copied from one or more systems, converted into a uniform format, and written to the new destination. This process is commonly referred to as extract, transform, load (ETL). ETL provides the means to combine disparate data from multiple sources and create a homogenous data set that can be analyzed in order to extract business intelligence from it.
During extraction, data is read from one or more sources and held in temporary storage for transformation and loading. An organization may extract data from its own internal systems, such as a transaction processing system that records all order activities or from external sources, such as data it purchases or obtains for free from other organizations.
Extraction is commonly broken down into two logical extractions methods:
During the transform stage, data is processed to make all data consistent in structure and format so that it all conforms to a uniform schema. A schema provides the structure and rules for organizing data in a relational database. The source and target database systems may use different schemas; for example, the source database may store shipping information in a Customer table, whereas the target database stores shipping information in a separate Shipping table. Or, the source table may have dates in the MM/DD/YYYY format, whereas the target uses the DD/MM/YYYY format. To successfully copy data from the source to the target, certain transformations must be made to ensure that the source data is in an acceptable format.
During the load operation, all newly transformed data is written to the target data warehouse for storage. Various mechanisms can be used to load data into the target warehouse, including the following:
ETL is commonly described as a three-step process primarily to make it easier to understand. In practice, ETL is not a series of clearly defined steps but more of a single process. As such, the sequence of events may vary. Depending on the approach, ETL may be more like one of the following:
Given the increasing volumes of data that organizations must capture and integrate into their data warehouses, Extract Transform Load often becomes a major bottleneck. Database administrators need to constantly revise their ETL procedures to accommodate variations in the data arriving from different sources. In addition, the volume and velocity of data can overwhelm an organization’s existing data warehouse storage and compute capabilities, leading to delays in producing time-sensitive reports and business intelligence. ETL operations often compete for the same storage and compute resources needed to handle data queries and analytics.
Fortunately, data warehousing technology has evolved to help reduce or eliminate the impact of the ETL bottleneck. For example, cloud data warehousing provides virtually unlimited storage and compute resources, so that ETL does not need to compete with queries and analytics for limited resources. In addition, data warehouse frameworks such as Hadoop take advantage of distributed, parallel processing to distribute work-intensive tasks such as ETL over multiple servers to complete jobs faster.
With the right tools and technologies in place, organizations can now stream diverse data from multiple sources into their data warehouses and query and analyze that data in near real time. If you or your team is in charge of procuring a new data warehouse solution for your organization, look for a solution that provides unlimited concurrency, storage, and compute, to avoid contention issues between ETL processes and people in the organization who need to use the same system to run queries and conduct analysis. Also look for a system that can live-stream data feeds and process structured, semi-structured, and unstructured data quickly and easily without complicated and costly ETL or ELT processes. In most cases, the ideal solution will be data warehouse built for the cloud.