9450 SW Gemini Drive #32865
Beaverton, Oregon, 97008-7105
In my previous article, Neural Network Hidden Layers, I presented a simple example of how multi-layer artificial neural networks learn. At a more basic level is the perceptron — a single-layer neural network. The perceptron history is worth looking at because it sheds light on how individual neurons within a neural network function. If you know how a perceptron functions, you know how an artificial neuron functions.
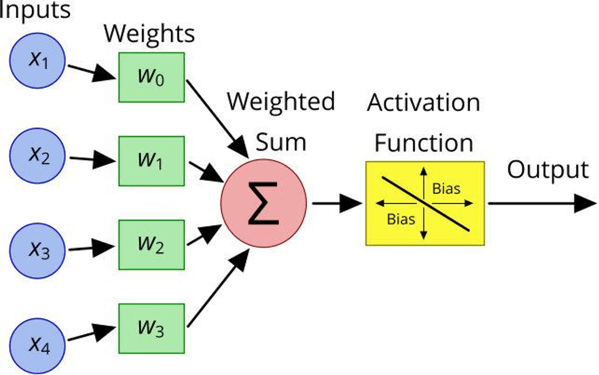
A perceptron consists of five components:
Basically, here's how a perceptron works:
Weights and bias are primarily responsible for enabling machine learning in a neural network. The neural network can adjust the weights of the various inputs and the bias to improve the accuracy of its binary classification system.
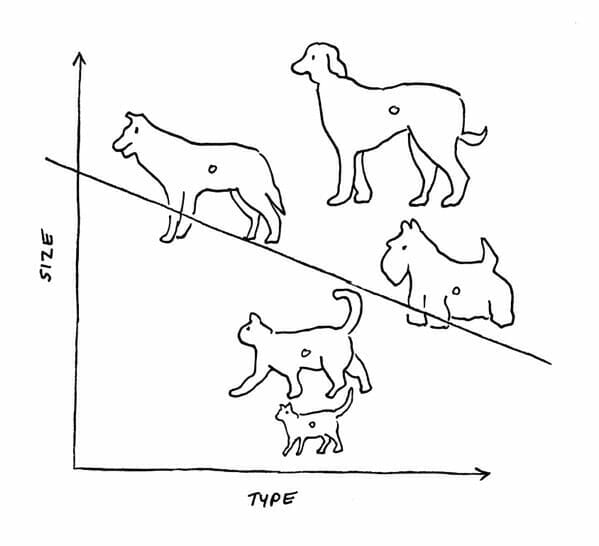
For example, the figure below illustrates how the output function of a perceptron might draw a line to distinguish between pictures of cats and dogs. If one or more dog pictures ended up on the line or slightly below the line, bias could be used to adjust the position of the line so it more precisely separated the two groups.
Frank Rosenblatt invented the perceptron in 1958 while working as a professor at Cornell University. He then used it to build a machine, called the Mark 1 Perceptron, which was designed for image recognition. The machine had an array of photocells connected randomly to neurons. Potentiometers were used to determine weights, and electric motors were used to update the weights during the learning phase.
Rosenblatt's goal was to train the machine to distinguish between two images. Unfortunately, it took thousands of tries, and even then the Mark I struggled to distinguish between distinctly different images.
While Rosenblatt was working on his Mark I Perceptron, MIT professor Marvin Minsky was pushing hard for a symbolic approach. Minsky and Rosenblatt debated passionately about which was the best approach to AI. The debates were almost like family arguments. They had attended the same high school and knew each other for decades.
In 1969 Minsky co-authored a book called Perceptrons: An Introduction to Computational Geometry with Seymour Papert. In it they argued decisively against the perceptron, showing that it would only ever be able to solve linearly separable functions and thus be able to distinguish between only two classes. Minsky and Papert also, mistakenly, claimed that the research being done on the perceptron was doomed to fail because of the perceptron's limitations.
Sadly, two years after the book was published, Rosenblatt died in a boating accident. Without Rosenblatt to defend perceptrons and with many experts in the field believing that research into the perceptron would be unproductive, funding for and interest in Rosenblatt's perceptron dried up for over a decade.
Not until the early 1980s did interest in the perceptron experience a resurgence, with the addition of a hidden layer in neural networks that enables these multi-layer neural networks to solve more complex problems.
Fueling the rise of machine learning and deep learning is the availability of massive amounts of data, often referred to as big data. If you wanted to create an AI program to identify pictures of cats, you could access millions of cat images online. The same is true, or more true, of other types of data. Various organizations have access to vast amounts of data, including charge card transactions, user behaviors on websites, data from online games, published medical studies, satellite images, online maps, census reports, voter records, economic data and machine-generated data (from machines equipped with sensors that report the status of their operation and any problems they detect). So what is the relationship between AI and big data?
This treasure trove of data has given machine learning a huge advantage over symbolic systems. Having a neural network chew on gigabytes of data and report on it is much easier and quicker than having an expert identify and input patterns and reasoning schemas to enable the computer to deliver accurate responses.
In some ways the evolution of machine learning is similar to how online search engines evolved. Early on, users would consult website directories such as Yahoo! to find what they were looking for — directories that were created and maintained by humans. Website owners would submit their sites to Yahoo! and suggest the categories in which to place them. Yahoo! personnel would then vet the sites and add them to the directory or deny the request. The process was time-consuming and labor-intensive, but it worked well when the web had relatively few websites. When the thousands of websites proliferated into millions and then crossed the one billion threshold, the system broke down fairly quickly. Human beings couldn’t work quickly enough to keep the Yahoo! directories current.
In the mid-1990s Yahoo! partnered with a smaller company called Google that had developed a search engine to locate and categorize web pages. Google’s first search engine examined backlinks (pages that linked to a given page) to determine the relevance and authority of the given page and rank it accordingly in its search results. Since then, Google has developed additional algorithms to determine a page’s rank (or relevance); for example, the more users who enter the same search phrase and click the same link, the higher the ranking that page receives. This approach is similar to the way neurons in an artificial neural network strengthen their connections.
The fact that Google is one of the companies most enthusiastic about AI is no coincidence. The entire business has been built on using machines to interpret massive amounts of data. Rosenblatt's preceptrons could look through only a couple grainy images. Now we have processors that are at least a million times faster sorting through massive amounts of data to find content that’s most likely to be relevant to whatever a user searches for.
Deep learning architecture adds even more power, enabling machines to identify patterns in data that just a few decades ago would have been nearly imperceptible. With more layers in the neural network, it can perceive details that would go unnoticed by most humans. These deep learning artificial networks look at so much data and create so many new connections that it’s not even clear how these programs discover the patterns.
A deep learning neural network is like a black box swirling together computation and data to determine what it means to be a cat. No human knows how the network arrives at its decision. Is it the whiskers? Is it the ears? Or is it something about all cats that we humans are unable to see? In a sense, the deep learning network creates its own model for what it means to be a cat, a model that as of right now humans can only copy or read, but not understand or interpret.
In 2012, Google’s DeepMind project did just that. Developers fed 10 million random images from YouTube videos into a network that had over 1 billion neural connections running on 16,000 processors. They didn’t label any of the data. So the network didn’t know what it meant to be a cat, human or a car. Instead the network just looked through the images and came up with its own clusters. It found that many of the videos contained a very similar cluster. To the network this cluster looked like this.

A “cat” from “Building high-level features using large scale unsupervised learning”
Now as a human you might recognize this as the face of a cat. To the neural network this was just a very common something that it saw in many of the videos. In a sense it invented its own interpretation of a cat. A human might go through and tell the network that this is a cat, but this isn’t necessary for the network to find cats in these videos. In fact the network was able to identify a “cat” 74.8% of the time. In a nod to Alan Turing, the Cato Institute’s Julian Sanchez called this the “Purring Test.”
If you decide to start working with AI, accept the fact that your network might be sensing things that humans are unable to perceive. Artificial intelligence is not the same as human intelligence, and even though we may reach the same conclusions, we’re definitely not going through the same process.
In my previous post Artificial Neural Networks, I explain what an artificial neural network (or simply a neural network) is and what it does. I also point out that what enables a neural network to perform its magic is the layering of neurons. A neural network consists of three layers of neurons — an input layer, one or more hidden layers, and an output layer.
The input and output layers are self-explanatory. The input layer receives data from the outside world and passes it to the hidden layer(s) for processing. The output layer receives the processed data from the hidden layer(s) and coveys it in some way to the outside world.
Yet, what goes on in the hidden layer(s) is more mysterious.
Early neural networks lacked a hidden layer. As a result, they were able to solve only linear problems. For example, suppose you needed a neural network to distinguish cats from dogs. A neural network without a hidden layer could perform this task. It could create a linear model like the one shown below and classify all input that characterizes a cat on one side of the line and all input that characterizes a dog on the other.
However, if you had a more complex problem, such as distinguishing different breeds of dogs, this linear neural network would fail the test. You would need several layers to examine the various characteristics of each breed.
Suppose you have a neural network that can identify a dog's breed simply by "looking" at a picture of a dog. A neural network capable of learning to perform this task could be structured in many different ways, but consider the following (admittedly oversimplified) example of a neural network with several layers, each containing 20 neurons (or nodes).
When you feed a picture of a dog into this fictional neural network, the input layer creates a map of the pixels that comprise the image, recording their positions and grayscale values (zero for black, one for white, and between zero and one for different shades of gray). It then passes this map along to the 20 neurons that comprise the first hidden layer.
The 20 neurons in the first hidden layer look for patterns in the map that identify certain features. One neuron may identify the size of the dog; another, its overall shape; another, its eyes; another, its ears; another, its tail; and so forth. The first hidden layer then passes its results along to the 20 neurons in the second hidden layer.
The neurons in the second hidden layer are responsible for associating the patterns found in the first layer with features of the different breeds. The neurons in this layer may assign a percentage to reflect the probability that a certain feature in the image corresponds to different breeds. For example, based solely on the ears in the image, the breed is 20% likely to be a Doberman, 30% likely to be a poodle, and 50% likely to be a Labrador retriever. The second hidden layer passes its results along to the third hidden layer.
The neurons in the third hidden layer compile and analyze the results from the second hidden layer and, based on the collective probabilities of the dog being a certain breed, determine what that breed is most likely to be. This final determination is then delivered to the output layer, which presents the neural network's determination.
While the example I presented focuses on the layers of the neural network and the neurons (nodes) that comprise those layers, the connections between the neurons play a very important role in how the neural network learns and performs its task.
Every neuron in one layer is connected to every neuron in its neighboring layer. In the example I presented, that's 400 connections between each layer. The strength of each connection can be dialed up or down to change the relative importance of input from one neuron to another. For example, each neuron in the first hidden layer can dial up or down its connection with each neuron in the input layer to determine what it needs to focus on in the image, just as you might focus on different parts of an image.
When the neural network is being trained with a set of test data, it is given the answers — it is shown a picture of each breed and labeled with the name of the breed. During this training session, the neural network makes adjustments within the nodes and between the nodes (the connections). As the neural network is fed more and more images of dogs, it fine-tunes its connections and makes other adjustments to improve its accuracy over time.
Again, this example is oversimplified, but it gives you a general idea of how artificial neural networks operate. The key points to keep in mind are that artificial neural networks contain far more connections than they contain neurons, and that they learn by making adjustments within and between neurons.